Open Knowledge Initiatives, IIIT-Hyderabad
Indian language digitisation's dilemmas
- By Pavan Santhosh (OKI, IIIT-H)
 Dnyaneshwari manuscript (1843 CE) - Two pages from the oldest surviving Marathi text, a 13th-century Bhagavad Gita commentary by Dnyaneshwar, digitised by the University of Arizona and the British Library Public domain
Image Credits: By Ms Sarah Welch, CC BY-SA 4.0
Digitisation is being undertaken by a wide range of individuals, organisations, institutions, and groups working in the field of Indian Languages. For a few decades, efforts to digitally preserve materials in Indian languages have been underway, ranging from small-scale collections to massive archives comprising millions of pages and images. Alongside government missions, which operate with official mandates and substantial resources, civil society groups, small organisations, and independent collectives play a vital role in documenting valuable literature and knowledge across languages. However, pre-existing inequalities and resource constraints often shape the scope of this work, influencing which materials and languages are digitised and which are not.
Several challenges limit the overall impact of these efforts. These include constraints imposed by copyright law and hosting platforms, a lack of institutional support, limited opportunities for shared learning and collaboration among organisations working across languages, and gaps in literary data and resource availability. In addition, only a small fraction of digitised materials is accessible to the public, and many are not provided in usable technical formats, such as Unicode text or well-structured metadata. Such collaboration could be particularly consequential for low-resource languages, where individual organisations rarely have the capacity to address documentation, digitisation, and access challenges on their own. While some organisations are addressing these issues and making gradual progress to fix these issues for their efforts, in parallel, early efforts toward building collaborative spaces exist, though they remain nascent and have yet to find broader support. A more coordinated and collaborative approach could significantly accelerate outcomes and ensure that the full benefits of digitisation are realised across all Indian languages: Read more
- Curated by Pavan Santhosh (OKI, IIIT-H)
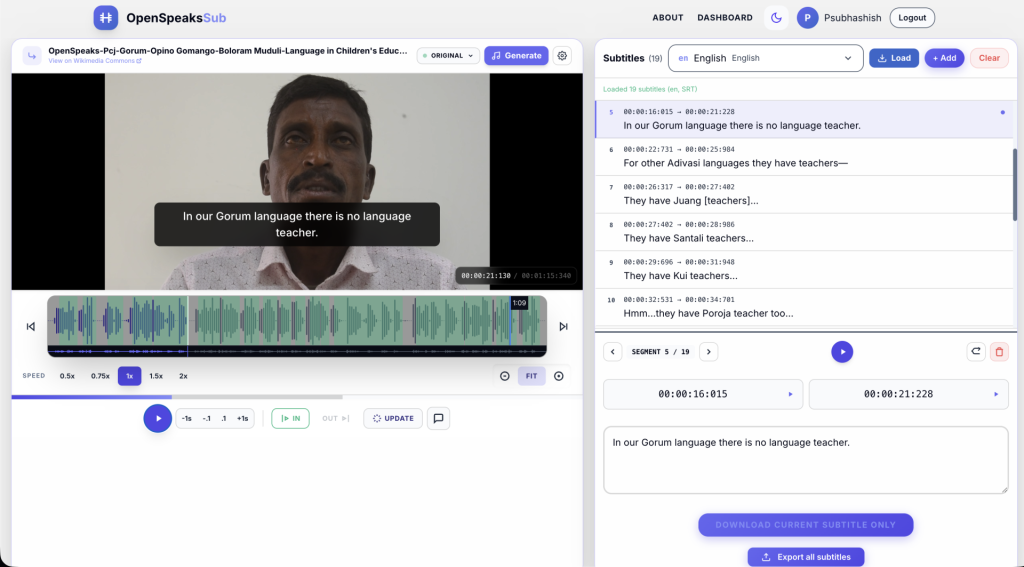
OpenSpeaks Archives Documents Endangered Indian Languages OpenSpeaks Archives, a Wikimedia-supported project, conducted field documentation of endangered Indian languages, including Gorum (Language which has no child speakers and between 600 and 6,000 adult speakers) and Juang in Odisha between July 2025 and March 2026. The project released an Oral History Framework that enables low-resource language recordings to be cited on Wikipedia, addressing a long-standing gap where oral knowledge has been excluded from open knowledge platforms. MORE DETAILS: Click here. Image Credits: OpenSpeaksSubtitler, Subhashish Panigrahi, CC BY-SA 4.0 MaNaSu Foundation completed digitising Three Crore Telugu Pages MaNaSu Foundation has announced the digitisation of three (3) crore pages of Telugu books and magazines. The work is being carried out at their centre in Varikuntapadu village, Andhra Pradesh. Founded in 2006, the non-profit makes public domain and freely licensed Telugu works freely accessible to everyone in phases.
MORE DETAILS: Project details | Apple App Store adds 10 Indian languages Apple added localised metadata support for ten Indian languages, Bangla, Gujarati, Kannada, Malayalam, Marathi, Odia, Punjabi, Tamil, Telugu, and Urdu, to App Store Connect, meaning developers can now optimise their apps for Indian language search for the first time. Google Play has supported several of these for years; Apple's move signals a significant shift in how the global app economy treats Indian languages.
MORE DETAILS: Announcement Image Credits and Rights: Apple Inc.; Reproduced for purposes of reporting; No affiliation with or endorsement by Apple is implied.
A Dedicated Malayalam Tokenizer to Improve AI Language Accuracy Santhosh Thottingal, a renowned Malayalam computing and Unicode expert, has released a dedicated Malayalam tokenizer for large language models. Generic AI systems often split Malayalam words into too many small fragments, increasing costs and reducing accuracy. This tokenizer, trained on a 15GB Malayalam corpus, reduces unnecessary fragmentation - an important step for Malayalam and other morphologically rich, low-resource languages in modern AI.
MORE DETAILS: Blog |
List of celebrations, commemorations and other important dates for Indic Languages. | Sindhi Language Day - Commemorates the inclusion of the Sindhi in the 8th Schedule of the Constitution in 1967.
|
| Birth Anniversary of Dr. B. R. Ambedkar - Architect of the Constitution of India; Jurist, academic, and central figure in the Dalit movement. (B. 1891)
|
| Birthday of Padma Sachdev - The Mother of Modern Dogri Poetry. (B. 1940)
|
| Birth Anniversary of Dr. Rajkumar - The cinematic icon whose cultural impact is inseparable from modern Kannada identity. (B. 1929)
|
| Birth Anniversary of Sri Sri - Srirangam Srinivasarao, or Sri Sri, is arguably the most important and revolutionary poet of modern Telugu Literature.
|
The Open Knowledge Initiatives (OKI) programme at IIIT Hyderabad is a strategic initiative with the aim of fostering language diversity and promoting equitable access to knowledge across the Indian subcontinent. We join hands with diverse communities to build inclusive, multilingual spaces for collaboration, innovation, and exchange. To learn more about Bahu Bhasa, please visit our website (https://bahubhasa.oki-india.org). Feedback & suggestions We value your inputs! Share your feedback, suggestions, or ideas about our programs and initiatives. Your perspectives help us better develop the newsletter further. Please write your thoughts to us at contact.oki@research.iiit.ac.in
Copyright and Licensing:
- Unless otherwise noted, all content in this newsletter is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License (CC BY-SA 4.0).
- All media files are similarly licensed under CC BY-SA 4.0 unless explicitly specified with alternative attribution.
- Any unlicensed third-party media used in this publication are included under fair use provisions for educational and non-commercial purposes.
| Disclaimer:
- This newsletter contains links to external websites. We are not responsible for the content or practices of third-party sites.
- Views and opinions expressed in contributed articles are those of the authors and do not necessarily reflect the official policy or position of OKI or IIIT-Hyderabad.
- Feel free to forward this newsletter to colleagues and friends interested in open knowledge and multilingual digital inclusion.
- While we strive for accuracy, information in this newsletter is provided "as is" for educational purposes. Please verify details independently before taking action.
|
|
.png)